Disruptor 는 LMAX 라는 영국 외환 거래소에서 개발해서 사용중인 java기반의 inter thread messaging library 이다. Disruptor 라는 특이한 이름은 java기반으로는 고성능 메시지 처리가 불가능하다는 고정 관념을 깨는 녀석이라는 의미와, java 7 의 Phaser 가 했던 것처럼 Star Trek 영화에 나오는 Disruptor 라는 광선총 종류라고 한다.
이 글에서는 disruptor가 기본적으로 어떻게 동작하는지 알아 보고 c++ 로 구현해 보고자 한다.
여기서 설명한 내용이 구현된 소스는 다음 위치에서 참고할수 있다.
https://github.com/jeremyko/disruptorCpp-IPC
가변길이 데이터 처리를 위해서는 약간 변형된 다음 소스를 참고.
https://github.com/jeremyko/disruptorCpp-IPC-Arbitrary-Length-Data
1. Queue vs Disruptor
설명을 위해서 생산자, 소비자 역할을 하는 쓰레드가 데이터를 주고 받는 경우를 한번 가정해보자.
예를 들어 2개의 생산자 p1, p2 가 2개의 소비자 c1, c2 를 위해 데이터 d1, d2 를 저장한다고 가정해 보자.
queue를 사용하는 경우엔 c1 과 c2 는 각각 d1, d2 데이터를 전부 수신하지 못한다.
큐에 들어간 작업들은 큐 소비자들에게 순차적으로 분배된다. 큐에 들어간 데이터 d1, d2 는 c1, c2에 분배되어 처리될 것이다. 즉 queue 구조는 작업 큐(work queue)의 개념이다.
반면 disruptor의 경우는 d1, d2 데이터가 모든 소비자 c1, c2 들에게 각각 모두 전달된다. 즉 c1도 d1, d2데이터를 전달받고, c2 또한 마찬가지이다.

2. Disruptor 동작 방식
2.1 Ring buffer
이것은 새로운 개념은 아니고 기존부터 존재하던 순환큐(circular queue)를 의미한다. disruptor 세계에서는 queue란 단어를 무척 혐오하기 때문에(^^) 대신 (magic) ring buffer 라고 부른다. disruptor 에서 모든 생산자의 메시지는 하나의 ring buffer에 저장된다.
ring 버퍼는 데이터 저장 위치 관리를 위한 cursor, next 내부 변수를 가진다.
next는 생산자가 데이터 저장을 위해 예약한 위치를 의미한다. cursor 는 생산자가 데이터 저장을 완료한 위치로, 소비자가 읽어가도 되는 위치를 의미한다. 이러한 next, cursor 접근은 모두 lock free로 이루어질 수 있다.
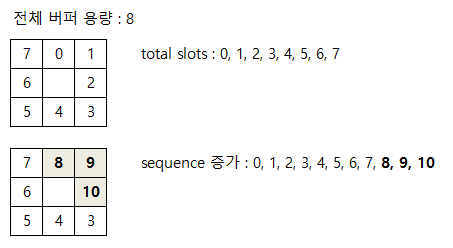
버퍼 내의 데이터 위치는 seq 번호로 나타낼 수 있는데 여기서 약간의 트릭이 사용된다. 예를 들어 전체 크기가 8인 ring버퍼를 가정해보자.
데이터가 저장됨에 따라 그 위치를 표시하기 위해서 순차적으로 증가하는 index를 사용할 것이다(0,1,2,3,4,5,6.. 이런 식).
그런데 index 7을 넘어가면 disruptor 에서는 index 가 다시 0으로 돌아가는 게 아니고 계속 증가하여 8,9,10... 이렇게 증가한다.
즉 버퍼내의 위치를 가리키는 sequence번호는 계속 증가하는 값이다.
그리고 이 sequence번호로부터 실제 slot 의 위치를 결정하기 위해서는 % (mod) 연산이 필요하다.
하지만 버퍼의 크기를 2의 배수로 제한하면 좀더 효율적으로 결정할수 있다.
예를 들어, 현재 sequence번호가 9라면 실제 버퍼에서의 위치는 9 % 8 =1 로 구할 수 있다.
하지만 2의 배수로 버퍼가 할당되어 있다면, index = sequence & (capacity - 1) 에 의해 빠르게 구할수 있다.
참고 : ring 버퍼 내 위치를 나타내기 위해 int64_t 자료 형이 사용되는데 이것의 최대값(INT64_MAX)을 가지고 대략 계산해보면 초당 천만 건 처리한다고 해도 약 3만년이나 걸리기 때문에 이 상황을 우려할 필요는 거의 없다.
2.2 생산자를 위한 처리
2.2.1 Claim
생산자가 메시지를 버퍼에 저장하기 위해서는 먼저 버퍼 내 사용할 위치를 예약 해야 한다. 이 작업을 claim 이라고 한다.
Claim호출이 성공하면 ring buffer 가 관리하는 next 위치를 증가시킨다.
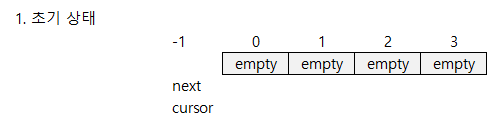
그런데 next 변수를 무조건 증가시키면 안되고 소비자의 현재 데이터 읽고 있는 위치를 고려해야 한다. 아직 소비자가 읽어가지 못한 위치에 다시 데이터를 덮어 쓰면 안되기 때문이다. 아래 그림은 버퍼의 용량이 4개이고, 1 생산자 1 소비자 가 사용하는 형태로, 현재 소비자는 0번 데이터가 저장되기를 대기하는 상황을 나타낸다.
아직 생산자가 데이터를 저장하지 않은 상태이므로 예약된 index는 없고 초기값 -1을 가지고 있다.

소비자가 0번 인덱스를 사용중인것은 아직 아무런 데이터도 읽지 못한것으로 판단되며,생산자가 Claim 을 3번 호출해서 0,1,2 번 index를 예약하고 데이터를 저장을 한 상태이다.

이 상태에서 생산자가 데이터 저장을 위해 다시 Claim을 호출해서 index를 예약 하려 한다면 소비자가 읽어가지 않은 0번 index데이터를 덮어쓰지 않게 하기 위해서 그 호출은 대기 상태로 들어간다.

가장 마지막으로 읽은 데이터의 index는 1 이 된다.

침범하지 못한다) 이므로 그곳에 데이터를 쓸수는 없고 생산자가 Claim을 호출하면 다시 대기 상태로 들어간다.

{kind=link}
생산자가 자신의 데이터를 저장하고 나서 commit 을 수행한다.
이때 입력 인자로 자신이 claim을 통해 할당 받은 index 를 넘겨준다. commit 을 통해서 ring 버퍼의 cursor 위치가 증가한다.
여기서 중요한 점은 생산자가 claim하여 할당 받은 버퍼 내 index 에 대해서 commit 을 수행한다고 해서 그 즉시 cursor 위치가 증가 하지 않는 다는 것이다.
생산자 A,B 가 존재하는 경우를 가정해보자.
생산자 A는 claim을 통해 index 0을, 생산자 B는 index 1을 할당 받았다.


이유는 이러한 체크를 통해서 큐가 지닌 FIFO 속성을 구현할 수 있기 때문이다.
즉, 생산자가 Claim을 통해 버퍼 내 인덱스를 할당 받은 순서대로 데이터 저장도 완료되며, 소비자가 가져가는 순서도 그와 동일하게 된다.
다시 예제로 돌아가서, 이제 생산자 A가 저장을 끝내고 commit 을 호출한다면 이때는 cursor가 정상적으로 증가되고, cursor위치 변화를 대기 중이던 생산자 B 역시 commit 처리가 진행되어 cursor가 다시 증가할 것이다.

2.3 소비자를 위한 처리
2.3.1 WaitFor
소비자가 ring 버퍼에서 데이터를 읽어오기 위해서는 WaitFor 메서드 호출을 통해서 ring 버퍼의 데이터 위치를 얻어야 한다.
WaitFor 메서드는 소비자가 읽을 ring 버퍼의 index를 돌려준다.
큐 기반의 방식과 틀린점은 WaitFor메서드 호출시 소비자는 자신이 이전에 읽어왔던 링버퍼의 index + 1의 값을 전달해줘야 한다.
만약 최초로 데이터를 수신하는 상황이라면 0을 전달한다.
만약 소비자가 여러번 재기동 되는 상황이면 이전까지 처리했던 마지막 index를 기억했다가 그 index + 1 의 값을 전달해야 한다.
흥미로운 점은 WaitFor 을 통해서 1개 데이터만 읽을 수 있는 게 아니라, 한번에 처리할 버퍼 index 범위를 얻을 수 있다는 점이다 (이를 batching effect로 표현하고 있다).
WaitFor호출을 하면 ring 버퍼의 현재 cursor위치를 보고 최대로 읽을 수 있는 index를 돌려준다.
소비자는 현재 자신이 읽은 최종 index 부터 WaitFor 메서드를 통해 반환된 index까지 여러 데이터를 한번에 처리할 수 있다.
2.3.2 CommitRead
소비자 또한 생산자와 마찬가지로, 해당 ring 버퍼의 인덱스에 대한 모든 작업이 끝나면 자신이 어느 지점까지 데이터를 읽었는지 저장을 해줘야 한다. 이 작업을 해줘야 생산자가 소비자의 위치를 참고해서 버퍼를 덮어쓰는 것을 방지할 수 있다.
이건 Disruptor 특징이기도 한데 놀랍게도(?) 모든 생산자는 모든 소비자의 ring 버퍼 내 현재 위치를 확인할 수 있다. 그리고 이를 통해서 데이터 덮어쓰기를 방지하기 위한 체크를 수행한다.
2.4 Claim, Wait Strategy
생산자의 Claim, 소비자의 WaitFor 메서드 호출 시 즉각 리턴 되지 않고 적정 조건을 만족 시킬 때까지 대기하는 경우가 발생한다. 예를 들어 생산자가 Claim 호출 시 다음 next 위치가 소비자 위치를 침범한다면 대기할 필요가 있다. Disruptor 에서는 이때 어떤 식으로 대기할 것이냐에 대한 방법을 Strategy 패턴으로 구현해 놓았다. 생산자, 소비자의 대기 전략의 종류는 다음과 같다.
2.4.1 생산자 Claim Strategy
생산자가 1개인 경우와 여럿인 경우 ring 버퍼내 next 위치를 증가시키기 위해 다른Claim 전략을 사용할수 있다.
SingleThreadedClaim : 만약 생산자가 1개 뿐이라면 ring 버퍼 내 next 증가는 단순 변수로도 가능하다. 이렇게 함으로서 성능상의 이점을 얻을 수 있다.
MultiThreadedClaim : 생산자가 여럿이라면 atomic연산으로 ring 버퍼 내 next 위치를 증가 시켜야 한다.
2.4.2 소비자 Wait Strategy
WaitFor 메서드 내부에서 데이터 위치를 loop 안에서 대기하는 동안 어떤 식으로 대기할 것인지 선택 가능하다. BusySpin, Yielding Strategy 는 수신할 데이터가 없는 경우에도 높은 CPU를 점유하기 때문에 유의해야한다.
BusySpin :
최고 성능을 보이지만 과도한 CPU 사용이 문제되는 경우를 조심해야 한다.
logical core갯수보다 소비자의 개수가 작고, 높은 성능, low latency가 요구될 때 사용된다.
Yielding :
다른 쓰레드에게 yield(양보) 수행한다. 성능 및 CPU 이용을 고려해서 좋은 선택이다.
Blocking :
lock, condition variable 을 사용하여 blocking 상태로 대기한다. 가장 느린 전략이지만 CPU 사용률이 중요한 경우 사용된다.
Sleeping :
loop 내부에서 sleep이 한번씩 걸린다. low latency 가 문제되지 않는 경우에 사용된다.
3. 구 현
현재 Linux, OS X 에서만 작동된다. c++11 이 지원되는 컴파일러가 필요하다 (Apple LLVM version 6.1.0, Linux gcc 4.8.4 에서 테스트됨).
https://github.com/jeremyko/disruptorCpp-IPC
가변길이 데이터 처리를 위해서는 약간 변형된 다음 소스를 참고.
https://github.com/jeremyko/disruptorCpp-IPC-Arbitrary-Length-Data
Disruptor는 원래 inter thread 라이브러리이다. 즉 하나의 프로세스가 생성한 thread 간에만 사용 가능하다. 그런데 아무래도 IPC 가 된다면 좀더 유용할듯하여 공유 메모리를 사용하게끔 작성되었다.
위에서 언급된 Claim, WaitFor, Commit등의 메서드들은 Disruptor 원래 코드에서는 ProducerBarrier, ConsumerBarrier라는 객체를 통해 이루어지지만 SharedMemRingBuffer 하나의 클래스에서 수행 하게 끔 작성되었다.
지금 구현된 소스는 기본적인 동작 원리만을 구현했기 때문에 원래 java 버전의 기능들이 모두 구현된 것은 아니라는것을 참고하길 바란다 (예: Claim Strategy 는 구현되지 않고 MultiThreadedClaim 만 사용한다).
tests 폴더에는 IPC, inter thread 테스트를 위한 예제가 있는데, 생산자가 1 ~ N 까지의 정수 데이터를 소비자에게 전달하고, 소비자는 수신한 모든 데이터를 sum해서 원하는 결과가 나오는지 검증하는 테스트 프로그램이다.
inter thread test :
생산자 소비자 thread간 데이터 전달을 test한다.
inter process test :
IPC 용도로 사용하는 경우 생산자, 소비자 process를 기동시켜 테스트한다. tests/inter_process폴더에 consumer 프로세스를 먼저 기동 후 producer 프로세스를 기동 시킨다. 모든 소비자가 생산자들이 저장한 값들을 수신하는 것을 확인 할수 있다.
inter_thread 실행 후 inter_process 수행하는 경우나 그 반대의 경우, 또는 버퍼 크기를 변경하거나 생산자, 소비자의 갯수가 변경되는 경우엔 반드시 공유메모리 초기화(ipcrm -M xxx)가 필요하다.
4. 생각 해 볼것들
실제 disruptor를 업무에 사용하게 된다면 많은 고민과 처리를 해줘야 할것으로 생각되는 부분이다. 만약 여러 소비자들중에서 일부 소비자가 제대로 데이터를 처리 못하는 상황이 된다면 모든 전체적인 메시지 처리또한 지연되게 된다.
비정상 상태의 소비자가 자신에게 부여되는 데이터를 정상 처리하지 못하면 나머지 소비자들은 하염없이 데이터를 기다리고만 있게 된다.
4.2 생산자가 여럿인 경우
disruptor는 일반적으로 1개의 생산자를 사용한다. 이 경우 생산자 내부 로직상으로 경쟁(contention)발생은 없다.
그런데 생산자의 갯수가 1을 초과하는 경우에는 Claim 메서드에서 다음 버퍼 위치를 얻기 위한 경쟁이 발생된다. 또한 소비자의 위치를 고려해서 데이터를 저장하는 방식 때문에, 생산자가 많아질수록 데이터 저장을 위해 대기하는 빈도가 늘어난다(소비자가 읽어야 할 데이터를 덮어쓰지 않기 위해서). 이런 사유로 일반적인 큐에 여러 생산자가 데이터를 저장하는 경우와 비교하면 disruptor방식의 처리 성능은 급격히 저하된다.
4.3 소비자가 자신의 index를 관리하는 점
disruptor 에서 소비자는 WaitFor메소드 호출시 자신이 다음에 읽을 링버퍼의 index를 넘겨줘야 한다. 그런데 만약 소비자가 재기동 되는 경우엔 이 index를 어딘가에보관했다가 다시 호출인자로 넘겨줘야 할것이다.
5. 결 론
MPMC(Multi Producer Multi Consumer),MPSC(Multi Producer Single Consumer),SPMC, SPSC 모두에 대해서 disruptor는 사용이 가능하다. 하지만 일반적으로 Single Producer 방식이 사용된다.
batching effect 는 상당히 참신하고 좋은 방식이라고 느껴진다. 링버퍼에서 처리할 위치를 매번 조회하는 방식이 아니고 한번에 처리 가능한 범위를 알수있기 때문에 소비자가 데이터를 처리하는 효율,성능이 좋아진다.
만약 여러 소비자들중 일부가 비정상 종료되거나 처리를 못하는 상황이면 전체 데이터 처리가 지연되는 특징이 있다.
이러한 disruptor의 특징을 알고 적절하게 사용하는 것이 중요해 보인다.
생산자가 여럿이고, 모든 소비자가 동일 메시지를 받을 필요가 없다면 disruptor사용은 재고가 필요할 듯하다. 반면 1개 생산자가 1개 혹은 여러 소비자들에게 동일한 데이터를 전달해야 한다면 disruptor 사용을 고려해 볼만하다. 그런데 이 경우는 앞선 언급된 비정상 소비자 처리가 중요한 이슈가 될것이다.
유용한 구현 도움이 많이 되었습니다! 코드를 보다보니 궁금한것이 있는데요...
답글삭제소비자의 최종 커밋시퀀스(코드내에서는 array_of_consumer_indexes[i])는 생산자 쓰레드 역시 claim 시에 참조하므로 atomic 변수를 사용해야 하는게 아닌지요?
예 맞습니다... 당연히 경쟁 상태를 제거해야 하는데 대체 무슨 생각으로 이랬는지, 방치한 지금이 부끄러워지는 순간이네요. 감사합니다.
답글삭제